Go: Working with JSON
Go: Working with JSON

This post will cover the following:
Why this post? I’ve recently been attempting to automate actions that I do on an everyday basis. Working with Splunk on a day to day basis I thought I might try some ‘automation’.
I have code working that pulls data from Splunk and pushes it into a Google Sheet. - Not 100% sure what to do with that yet, but I was thinking some type of trend analysis.
Also, it was not easy to find the right documentation, so this is my attempt to help others that try this.
Splunk Enterprise, Splunk Free Enterprise, or Splunk Enterprise Installed.
Please Note If this is a prod system or Splunk Enterprise, the API may not be accessible remotely. As such the code will need to be installed and executed locally on the system. - I am currently investigating how to make the API remotely accessible.
Additionally,if this is a prod system, it is best to use Oauth authentication. Some documentation can be found here
Splunk Host = 192.168.1.130
Splunk license has been changed to a free licence
The documentation states that :
You can use the Splunk Enterprise SDK for Python to perform a variety of actions in Splunk Enterprise, including searching data, developing custom UIs, and managing configurations for your instance.
So how can we connect to Splunk?
If you go to the documentation page here for installation steps, it will suggest using pip or setup.py. For my Linux enviornment this would not work.
The error was:
ModuleNotFoundError: No module named 'splunklib'
Googling this shows the solution is just to install the SDK and follow the documentation. I probably had my path incorrect.
Anyhow, if you run into this error, the solution for me was to clone the github repo and placed my files in there.
Like so:


Naturally, I named the file splunklib.py - due to fighting attempting to have splunklib module work.
The splunklib.client will be used to connect to Splunk.
Googling the client shows:

It is also within the Splunk Developer Documentation “How to Connect”, which is what I used to ensure my connection was working.
The example code below, will print out the app names. This is great to ensure you can connect to the Splunk API.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import splunklib.client as client
HOST = "localhost"
PORT = 8089
USERNAME = "admin"
PASSWORD = "yourpassword"
# Create a Service instance and log in
service = client.connect(
host=HOST,
port=PORT,
username=USERNAME,
password=PASSWORD)
# Print installed apps to the console to verify login
for app in service.apps:
print app.name
Once running, the code connects, authenticates and replies with the apps installed:
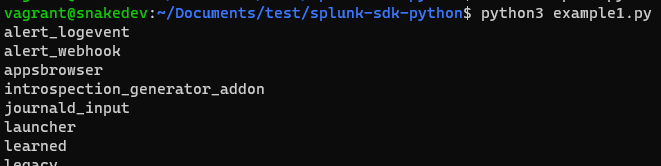
Please Note The above credentials will work with Enterprise Splunk and Enterprise Free Splunk.
However, if you have changed the license over to “Free Splunk”, there is technically no authentication. A way to test this, is by going to you Splunk instance via the web browser and it will automatically log in. There will not be a Splunk Username and Password screen.Information here
As mentioned above I have the free version, so my credentials are the following:
So currently, the code is able to connect to Splunk and print out the Apps. How can a search be run?
Jumping to the SDK again, there is a nicely titled article that is useful. Titled: “How to run searches and jobs using the Splunk Enterprise SDK for Python”
There are 4 types of searches. As I just wanted to create a quick search (it does not take long to process) I opted for the One-Shot search. As explained below, the search runs immediately and returns the results once completed.
One-shot: A one-shot search is a blocking search that is scheduled to run immediately. Instead of returning a search job, this mode returns the results of the search once completed. Because this is a blocking search, the results are not available until the search has finished.
This just allows for a search to run, without code being required that checks if the search is completed. It just waits. (Code that checks if a search is done will be shown below.)
Issues will occur if the one-shot code is copy and pasted. It does not include how to connect. The issue I found with this page was that it did not show the full code of connecting and running a search. To connect successfully, the code from above needs to be included,
The example code is:

The example code and the connection code becomes the below:
Please note: I changed the query to give an average of CPU used, as I have the Linux tech add-on installed. The query is the same regardless.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#!/usr/bin/python3
from __future__ import absolute_import
from __future__ import print_function
import splunklib.client as client
import splunklib.results as results
HOST = "192.168.1.130"
PORT = 8089
USERNAME = "admin"
PASSWORD = ""
# Create a Service instance and log in
service = client.connect(
host=HOST,
port=PORT,
username=USERNAME,
password=PASSWORD)
#searches for previous day
kwargs_oneshot = {"earliest_time":"@d"}
#search being run
searchquery_oneshot = "search index=main PercentMemory=* | stats avg(PercentMemory)"
#running and storing results
oneshotsearch_results = service.jobs.oneshot(searchquery_oneshot, **kwargs_oneshot)
# Get the results and display them using the ResultsReader
reader = results.ResultsReader(oneshotsearch_results)
for item in reader:
print(item)
print(item['avg(PercentMemory)'])
This is effectively the same query as:
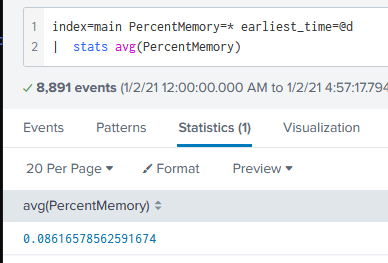
Prior to using (or finding) the Splunk SDK, I learned how to connect to Splunk with Python without the SDK.
Following the Documentation searches can be created with curl. With a query such as:
curl -u admin:changeme -k https://localhost:8089/services/search/jobs -d search="search *"```
Then the status of the search needs to be checked to ensure it has finished:
``` bash
curl -u admin:changeme -k https://localhost:8089/services/search/jobs/1258421375.19
and the results can be returned with:
curl -u admin:changeme \
-k https://localhost:8089/services/search/jobs/1258421375.19/results/ \
--get -d output_mode=csv
There is even a Python example given. However this one does not search if the job is complete.
Example from the Documentation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from __future__ import print_function
from future import standard_library
standard_library.install_aliases()
import urllib.request, urllib.parse, urllib.error
import httplib2
from xml.dom import minidom
baseurl = 'https://localhost:8089'
userName = 'admin'
password = 'password'
searchQuery = '| inputcsv foo.csv | where sourcetype=access_common | head 5'
# Authenticate with server.
# Disable SSL cert validation. Splunk certs are self-signed.
serverContent = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/auth/login',
'POST', headers={}, body=urllib.parse.urlencode({'username':userName, 'password':password}))[1]
sessionKey = minidom.parseString(serverContent).getElementsByTagName('sessionKey')[0].childNodes[0].nodeValue
# Remove leading and trailing whitespace from the search
searchQuery = searchQuery.strip()
# If the query doesn't already start with the 'search' operator or another
# generating command (e.g. "| inputcsv"), then prepend "search " to it.
if not (searchQuery.startswith('search') or searchQuery.startswith("|")):
searchQuery = 'search ' + searchQuery
print(searchQuery)
# Run the search.
# Again, disable SSL cert validation.
print(httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs','POST',
headers={'Authorization': 'Splunk %s' % sessionKey},body=urllib.parse.urlencode({'search': searchQuery}))[1])
The base authentication information is the same again:

A request needs to be made with the username and password encoded like the following:
1
2
3
4
serverContent = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/auth/login',
'POST', headers={}, body=urllib.parse.urlencode({'username':userName, 'password':password}))[1]
This creates a session key, to be used when creating a search.
As such this is stored within the sessionKey variable like so:
1
sessionKey = minidom.parseString(serverContent).getElementsByTagName('sessionKey')[0].childNodes[0].nodeValue
Once authenticated, the Session key is used along with the search query to run the search like so:
1
2
3
response = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs','POST',
headers={'Authorization': 'Splunk %s' % sessionKey},body=urllib.parse.urlencode({'search': searchQuery}))[1]
This gives a simple XML response which includes the SID:

To identify a finished ‘job’ (search query) the SID of the search needs to be identified. This is seen in the screenshot above when running a search.
So, to grab this, BeautifulSoup is used.
1
2
3
soup = BeautifulSoup(response.decode(), 'html.parser')
searchSID=soup.response.sid.string
print("SID: ", searchSID)
Which is stored in the searchSID variable:

This SID is then searched for in the ‘jobs’ url path. A loop is created until the “isDone” value is found.
The jobs URL is
'/services/search/jobs/
and then the searchSID is added to create the full URL:
1
print(baseurl + '/services/search/jobs/' + searchSID)
A request to the server is created and executed to identify if the job has finished:
1
testFinish = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs/' + searchSID , method="GET", headers={'Authorization': 'Splunk %s' % sessionKey})[1]
The response from searching if a job is ‘done’ is quite large.
Grepping for “isDone” will show a value of 0 or 1:

<s:key name="isDone">1</s:key>
Where a value of 1 is a search is complete and results are ready. A value of 0 isthe opposite.
Having identified the tag and value needed, a for loop is created, checking every 3 seconds if the job is done.
Using beautifulSoup to identify the isDone tag can be done with:
1
isDone=finishCheck.find('s:key',{"name":"isDone"})
The loop looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
while isDone == 0:
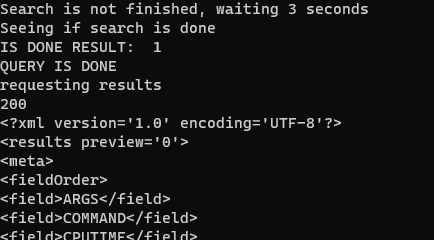
print("Search is not finished, waiting 3 seconds")
time.sleep(3)
print("Seeing if search is done")
#parsing response#
testFinish = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs/' + searchSID , method="> headers={'Authorization': 'Splunk %s' % sessionKey})[1]
finishCheck = BeautifulSoup(testFinish.decode(), 'lxml')
isDoneYet=finishCheck.find('s:key',{"name":"isDone"})
print("IS DONE RESULT: ", isDoneYet.text)
if int(isDoneYet.text) == 1:
isDone += 1
print("QUERY IS DONE")
The following image shows the loop in actions:
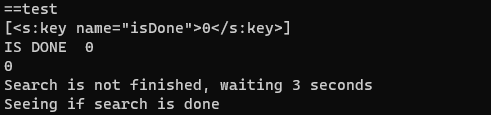
Once the job has been identified as complete, the results are ready to be collected.
This is simply done by requesting the job number with results:
1
response2 = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs/' + searchSID +'/results/', method="GET", headers={'Authorization': 'Splunk %s' % sessionKey})
From this, the results can be printed:
1
print(response2[1].decode())
The following image shows the loop finishing and requesting the results:
Using BeautifulSoup, the formating and information presented can be adjusted/improved.
The code in full is below, with extra print statements and comments as I was testing:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
from __future__ import print_function
from future import standard_library
standard_library.install_aliases()
import urllib.request, urllib.parse, urllib.error
import httplib2
from xml.dom import minidom
import re
from bs4 import BeautifulSoup
import time
#import splunklib
baseurl = 'https://x.x.x.x:8089'
userName = 'admin'
password = ''
searchQuery = 'index=* | head 5'
# Authenticate with server.
# Disable SSL cert validation. Splunk certs are self-signed.
serverContent = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/auth/login',
'POST', headers={}, body=urllib.parse.urlencode({'username':userName, 'password':password}))[1]
sessionKey = minidom.parseString(serverContent).getElementsByTagName('sessionKey')[0].childNodes[0].nodeValue
# Remove leading and trailing whitespace from the search
searchQuery = searchQuery.strip()
# If the query doesn't already start with the 'search' operator or another
# generating command (e.g. "| inputcsv"), then prepend "search " to it.
if not (searchQuery.startswith('search') or searchQuery.startswith("|")):
searchQuery = 'search ' + searchQuery
print("The query being run: " + searchQuery)
# Run the search.
# Again, disable SSL cert validation.
print("response to job creation:")
response = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs','POST',
headers={'Authorization': 'Splunk %s' % sessionKey},body=urllib.parse.urlencode({'search': searchQuery}))[1]
soup = BeautifulSoup(response.decode(), 'html.parser')
# print(soup.prettify())
# print(soup.response.sid.string)
searchSID=soup.response.sid.string
print(searchSID)
print("===testing if finished")
print(baseurl + '/services/search/jobs/' + searchSID)
testFinish = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs/' + searchSID , method="GET",
headers={'Authorization': 'Splunk %s' % sessionKey})[1]
print(testFinish[1])
finishCheck = BeautifulSoup(testFinish.decode(), 'lxml')
print(finishCheck.prettify())
print("============")
up = finishCheck.find("content")
print("==CHILDREN=")
print(finishCheck.find_all('s:key'))
print("==test")
print(finishCheck.find_all('s:key',{"name":"isDone"}))
isDone=finishCheck.find('s:key',{"name":"isDone"})
isDone = int(isDone.text)
print("IS DONE " , isDone)
print(isDone)
while isDone == 0:
print("Search is not finished, waiting 3 seconds")
time.sleep(3)
print("Seeing if search is done")
#parsing response#
testFinish = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs/' + searchSID , method="GET",
headers={'Authorization': 'Splunk %s' % sessionKey})[1]
finishCheck = BeautifulSoup(testFinish.decode(), 'lxml')
isDoneYet=finishCheck.find('s:key',{"name":"isDone"})
print("IS DONE RESULT: ", isDoneYet.text)
if int(isDoneYet.text) == 1:
isDone += 1
print("QUERY IS DONE")
print("requesting results")
response2 = httplib2.Http(disable_ssl_certificate_validation=True).request(baseurl + '/services/search/jobs/' + searchSID +'/results/', method="GET", headers={'Authorization': 'Splunk %s' % sessionKey})
print(response2[0].status)
print(response2[1].decode())
Go: Working with JSON
TL;DR Using short-lived secrets to access a database is much more secure than standard credentials
I recently received my AWS Solutions Architect Associate Cert, and I inadvertently learned more about Ops and DevOps in respect to automation, deployment an...
This post will cover the following: Connecting to Splunk with the Python SDK, executing a search and receiving the results Connecting to Splunk without ...
TL;DR: Create Logstash conf.d file to allow Winlogbeat to be ingested into Logstash. Change Winlogbeat config file to use Logstash instead of Elasticsearch.
TL;DR Enable-PSRemoting Invoke-Command
I have been working on Windows and needed to connect to a Network Interface (NIC). I ran into problems, here is what I learned and hope it saves the same tro...
I have been using tcpdump recently and wanted to note down some of the commands Y’know, for future reference.
Today I was trouble shooting a machine at work. I did not have access via RDP or VNC, so I used SSH to forward my traffic to the host so I could access a URL.
I participated in a DevSecOps type workshop on Saturday (May 9th) in which we created some GitHub Actions. This is a post to solidify the learning and be a c...
This post is a cheat sheet for removing values from a Slice (technically creating a new slice).
On April 25th I was fortunate enough to participate in the Trend Micro Threat Defense workshop.
Since I blogged about my experience at OpenSoc, I wanted to expand on the value I found in my eLearnSecuirty Incident Response course. What you will find bel...
So Thursday (April 9th) I participated in an online blue team defense simulation event, known as OpenSOC.
I have been working with Golang strings and how to manipulate them. Working from other blogs posts I’ve found. When I sit down to code, I seem to forget ever...
its workings
You’ll find this post in your _posts directory. Go ahead and edit it and re-build the site to see your changes. You can rebuild the site in many different wa...
Blog from home installed jekyll on home PC, pulled GH repo. done :) (not that easy)
2nd blog post this is some wording